What is topic modeling in text analytics?
 Topic modeling is the process of assembling a set of recurring topics within a body of text. It also involves defining a mechanism for categorizing the individual comments into one or more of those topics. Using topic modeling, data can be mined at scale to discover frequently used phrases or expressions within the text.
Topic modeling is the process of assembling a set of recurring topics within a body of text. It also involves defining a mechanism for categorizing the individual comments into one or more of those topics. Using topic modeling, data can be mined at scale to discover frequently used phrases or expressions within the text.
Why is it useful in market research?
It’s estimated that as much as 90% of the consumer data available in 2019 was unstructured — think social media, review sites, and surveys with open-ended questions — and the amount of data defined as unstructured is growing as fast as 55% per year.* Text analytics systems empower organizations to mine this sea of data and uncover what consumers are thinking. Topic classification is one of the core capabilities of these modern systems.
Unstructured data is of enormous value to organizations of all kinds because it provides an unfettered view into consumers’ minds; however, tapping into it can be challenging. Successfully classifying comments into topics is part of an overall approach that enables organizations to understand consumers’ thoughts, opinions, and ideas.
How is topic modeling done?
The challenge of categorizing consumer comments is nothing new. Market researchers and others have developed a wide range of approaches and techniques, while advancements in modern machine learning and artificial intelligence are opening new doors in topic modeling.
Manual topic classification
Traditional human coding remains an effective technique for some situations but has its downfalls, like the issues of replicability across datasets. A manual method may also be too costly or time-consuming to apply effectively to extensive data collection efforts, such as ongoing research.
Word spotting
Simple-to-apply techniques such as word or phrase counting can be useful in some cases. However, they often struggle to identify nuance, uncover “aha!” situations, or properly group semantically similar yet lexically diverse words (e.g., car vs. vehicle vs. truck or bill vs. invoice vs. receipt).
Machine learning
The latest deep learning, artificial intelligence techniques are built around language models harvested from large swaths of the web. These technologies combine:
- Large training datasets
- The latest in language encoding (e.g., transformers)
- Advancements in feature optimization
This combination rapidly identifies salient clusters of words or phrases and classifies comments into high-level topics that practitioners can use to mine a collection of consumer comments quickly.
 Unstructured data is complex and so are the tools used to analyze it. Make sure you’re not falling for one of these five common text analytics misconceptions — but here's what to do about it if you are.
Unstructured data is complex and so are the tools used to analyze it. Make sure you’re not falling for one of these five common text analytics misconceptions — but here's what to do about it if you are.
Choosing the best topic modeling approach for text analytics
How organizations leverage the available technologies and approaches is critical to maximizing learning and enabling impactful business decisions. The first thing to remember is that new does not always mean better, and old does not always mean obsolete.
Within the text analytics space, there is a need for a range of methodologies to satisfy the breadth of use cases an organization might have. Consider these examples:
A single, open-ended question survey
An organization collects 250 survey results containing an open-ended question like, “How do you feel about the ad campaign you just watched?” This highly specific situation may best be handled by manually classifying the comments. While this approach requires human effort, it can be performed in a relatively small amount of time and is likely to do a very good job of covering the range of what consumers say. This technique benefits from human practitioners who are knowledgeable in the business domain.
A survey with multiple open-ended questions
2,500 consumers respond to a survey focused on testing out new product names, logos, or marketing statements. The survey contains several open-ended questions like, “What specifically do you dislike about this?” and “How could this be improved?”
In this case:
- A collection of previously used topic classifications using a Boolean search approach is useful; however, layering additional approaches will improve topic coverage.
- Word or phrase counting can be suitable: Since the dataset is small and the consumer comments are focused, recurring word or phrase usage is easy to identify and organize.
- AI-based topic models can also be viable, although they may require additional time to curate and understand properly.
NPS surveys
An ongoing Net Promoter Score (NPS) survey asks, “Why do you rate NPS this way?” Customer experience research tends to produce high volumes of comments that quickly outpace the capacity to manually code the responses.
A pre-built model that categorizes comments around known areas of interest is often the best approach. However, augmenting the pre-built model with an automated AI-based topic model can be helpful to be sure that emerging topics are caught and categorized correctly. This also ensures that those “aha!” moments are not missed.
Online reviews or social media posts
Online review sites and social media posts contain a wealth of information that can inform an organization not just about its performance, but also about the performance of its competitors. AI-based, automatic topic models prove ideal for this scenario, where monitoring competition for emerging opportunities or challenges is the highest priority. AI is a great option because of the dynamic nature of the comments and the infrequency of reviewing.
A best practice in topic modeling for text analytics
Many text analytics tools in the market let users compose their own topic classifications for both single-use and ongoing needs. Bellomy’s Text Analytics tool provides an additional option: managed topic models.
Bellomy’s models for the utility; retail and supermarket; finance, banking, and insurance; and consumer packaged goods (CPG) industries are not mere lists of words or phrases that group together. Instead, they combine linguistic ontologies, rule-based classification, Boolean criteria, and deep learning techniques for enhanced accuracy and classification.
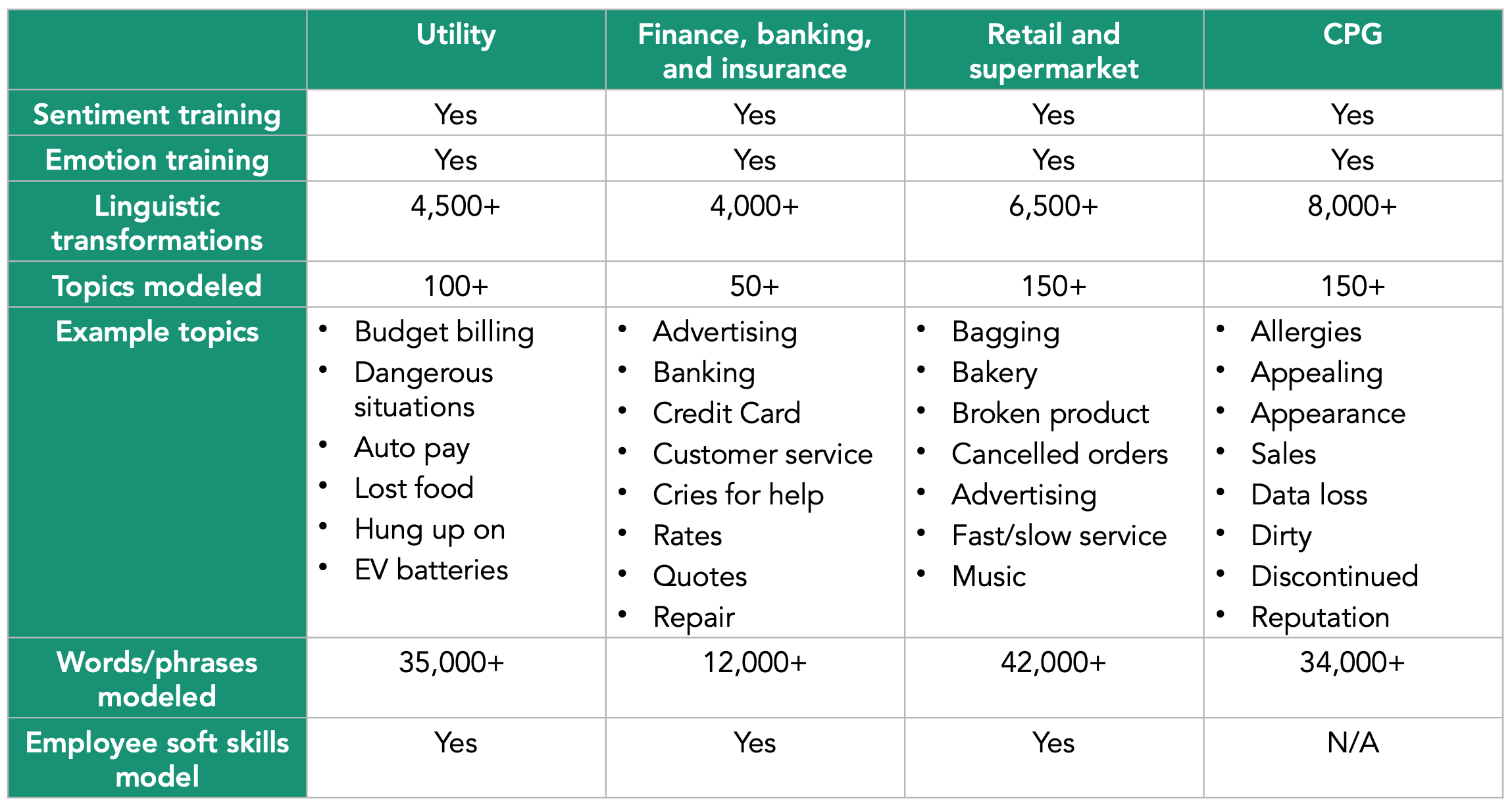
Continuous improvement in topic modeling
Managed topic models may be used alone but usually serve as a starting point for refining a dataset's final topic list. Bellomy’s text analytics specialists curate and maintain the tool’s topic models on an ongoing basis, reducing the burden for clients to fine-tune their view of the data. The team also monitors changes to determine when these models should be modified and improved or when to add new topics. Bellomy’s Text Analytics tool allows users to develop additional topics when they notice patterns emerging within comments.
Although these managed topic models do not replace the need for other techniques, they can significantly streamline organizations’ efforts to expeditiously uncover the meaning behind consumer feedback.
Tapping into topic modeling for deeper customer insights
Tools that limit the use cases and topic modeling approaches can result in missed opportunities or frustration when addressing new challenges. Bellomy’s Text Analytics tool enables organizations to apply the best topic classification approach to their challenge, leading to a greater understanding of what customers want, need, and expect.
Get a free demo of Bellomy’s Text Analytics tool to see how your organization can use it to uncover powerful insights.
*Bernard Marr, Forbes. “What Is Unstructured Data And Why Is It So Important To Businesses? An Easy Explanation For Anyone.“






